
| Online Judge | Online Exercise | Online Teaching | Online Contests | Exercise Author |
|
F.A.Q Hand In Hand Online Acmers |
Best Coder beta VIP | STD Contests DIY | Web-DIY beta |
Difference of Clustering
Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total Submission(s): 827 Accepted Submission(s): 304
Problem Description
Given two clustering algorithms, the old and the new, you want to find the difference between their results.
A clustering algorithm takes many $member\ entities$ as input and partition them into $clusters$. In this problem, a member entity must be clustered into exactly one cluster. However, we don’t have any pre-knowledge of the clusters, so different algorithms may produce different number of clusters as well as different cluster IDs. One thing we are sure about is that the $member IDs$ are stable, which means that the same member ID across different algorithms indicates the same member entity.
To compare two clustering algorithms, we care about three kinds of relationship between the old clusters and the new clusters: split, merge and 1:1. Please refer to the figure below.
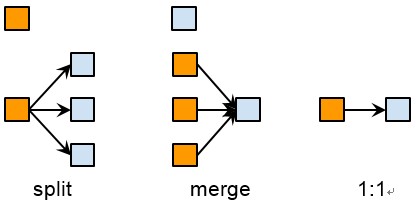
Let’s explain them with examples. Say in the old result, m0, m1, m2 are clustered into one cluster c0, but in the new result, m0 and m1 are clustered into c0, but m2 alone is clustered into c1. We denote the relationship like the following:
● In the old, c0 = [m0, m1, m2]
● In the new, c0 = [m0, m1], c1 = [m2]
There is no other members in the new c0 and c1. Then we say the old c0 is split into new c0 and new c1. A few more examples:
● In the old, c0 = [m0, m1, m2]
● In the new, c0 = [m0, m1, m2].
This is 1:1.
● In the old, c0 = [m0, m1], c1 = [m2]
● In the new, c0 = [m0, m1, m2]
This is merge. Please note, besides these relationship, there is another kind called “n:n”:
● In the old, c0 = [m0, m1], c1 = [m2, m3]
● In the new, c0 = [m0, m1, m2], c1 = [m3]
We don’t care about n:n.
In this problem, we will give you two sets of clustering results, each describing the old and the new. We want to know the total number of splits, merges, and 1:1 respectively.
A clustering algorithm takes many $member\ entities$ as input and partition them into $clusters$. In this problem, a member entity must be clustered into exactly one cluster. However, we don’t have any pre-knowledge of the clusters, so different algorithms may produce different number of clusters as well as different cluster IDs. One thing we are sure about is that the $member IDs$ are stable, which means that the same member ID across different algorithms indicates the same member entity.
To compare two clustering algorithms, we care about three kinds of relationship between the old clusters and the new clusters: split, merge and 1:1. Please refer to the figure below.
Let’s explain them with examples. Say in the old result, m0, m1, m2 are clustered into one cluster c0, but in the new result, m0 and m1 are clustered into c0, but m2 alone is clustered into c1. We denote the relationship like the following:
● In the old, c0 = [m0, m1, m2]
● In the new, c0 = [m0, m1], c1 = [m2]
There is no other members in the new c0 and c1. Then we say the old c0 is split into new c0 and new c1. A few more examples:
● In the old, c0 = [m0, m1, m2]
● In the new, c0 = [m0, m1, m2].
This is 1:1.
● In the old, c0 = [m0, m1], c1 = [m2]
● In the new, c0 = [m0, m1, m2]
This is merge. Please note, besides these relationship, there is another kind called “n:n”:
● In the old, c0 = [m0, m1], c1 = [m2, m3]
● In the new, c0 = [m0, m1, m2], c1 = [m3]
We don’t care about n:n.
In this problem, we will give you two sets of clustering results, each describing the old and the new. We want to know the total number of splits, merges, and 1:1 respectively.
Input
The first line of input contains a number $T$ indicating the number of test cases ($T≤100$).
Each test case starts with a line containing an integer $N$ indicating the number of member entities ($0≤N≤10^6$ ). In the following $N$ lines, the $i$-th line contains two integers c1 and c2, which means that the member entity with ID i is partitioned into cluster c1 and cluster c2 by the old algorithm and the new algorithm respectively. The cluster IDs c1 and c2 can always fit into a 32-bit signed integer.
Each test case starts with a line containing an integer $N$ indicating the number of member entities ($0≤N≤10^6$ ). In the following $N$ lines, the $i$-th line contains two integers c1 and c2, which means that the member entity with ID i is partitioned into cluster c1 and cluster c2 by the old algorithm and the new algorithm respectively. The cluster IDs c1 and c2 can always fit into a 32-bit signed integer.
Output
For each test case, output a single line consisting of “Case #X: A B C”. $X$ is the test case number starting from 1. $A$, $B$, and $C$ are the numbers of splits, merges, and 1:1s.
Sample Input
2 3 0 0 0 0 0 1 4 0 0 0 0 1 1 1 1
Sample Output
Case #1: 1 0 0 Case #2: 0 0 2
Source
| Home | Top |
Hangzhou Dianzi University Online Judge 3.0 Copyright © 2005-2024 HDU ACM Team. All Rights Reserved. Designer & Developer : Wang Rongtao LinLe GaoJie GanLu Total 0.000000(s) query 1, Server time : 2024-11-25 06:12:31, Gzip enabled |
Administration |